

How to Train ChatGPT on Your Data for More Accurate AI Writing
ChatGPT delivers amazingly capable AI text generation out of the box. But training it on your own custom data takes things to the next level.
In this guide, we’ll cover step-by-step
how to train ChatGPT on your data to make its outputs more accurate, relevant, and aligned with your business needs.
Why Train Your Own GPT Model?
ChatGPT was pre-trained on a massive dataset scraped from the public internet. This enables it to converse naturally and generate coherent text on nearly any topic.
However, because ChatGPT lacks exposure to your business, it can have limitations including:
- Generates content with incorrect industry facts/terminology
- Writes in a generic voice vs your brand style
- Struggles tailoring text to your specific offerings
- Outputs irrelevant or biased text
The Benefits of Training ChatGPT on Custom Data
Fine-tuning builds on ChatGPT's existing knowledge by continuing to train it on new examples of text that you provide.
As ChatGPT ingests more data that is specific to your needs, it learns to refine its language outputs to align better with the tone, style, accuracy, and topics you want.
Some key ways providing your own text examples trains ChatGPT:
Teaches ChatGPT New Business Information
By providing your brand voice guidelines, past marketing materials, and other examples of your messaging, ChatGPT will learn to write new copy matching your tone.
Rather than dull, generic-sounding content, it will create text with the style, language, and personality your brand embodies.
For instance, an edgy lifestyle brand could teach ChatGPT's writing to mirror their irreverent tone that resonates with their target demographic.
The more data you can provide that exemplifies your ideal outputs, the better ChatGPT will become at delivering personalized, high-quality content tuned to your needs.
Improves Accuracy & Writing Quality
When ChatGPT has your business knowledge ingrained, you'll spend far less time fixing awkward or incorrect outputs before publishing.
This way, the
relevance, accuracy, and branding will be baked in from the start.
Personalizes tone & voice
For example, if you want to create AI-generated blog posts or other marketing content, you'll want it to sound like yourself or your brand's voice.
By training the model on your own writings or your company's documents, you can get AI-generated text that matches your desired tone and style.
Steps to Train AI on Your Custom Knowledge Base
Multiple options exist for training your own ChatGPT model based on your budget, data availability, and technical expertise.

1.) Gathering Your Data
The first step is to gather the data you want to train ChatGPT on.
Pull together as many of your business documents into one unified dataset, such as:
- Product documentation - User manuals, technical specifications, brochures
- Website pages - Especially FAQs, "About Us", product category pages
- Marketing collateral - Whitepapers, case studies, newsletters, blogs
- Client onboarding - Welcome packets, account setup docs, administration manuals
- Support forums - Common questions/answers from customers
- Transcripts from meetings - If you have recordings or transcripts of conversations between humans in your domain, this is excellent data to train ChatGPT. The conversations will teach ChatGPT the language, tone, and flow of discussions in your area of focus.
- FAQs and Other Documentation - Do you have a knowledge base of frequently asked questions, responses, or other documentation? This written content is also useful for training as it provides examples of the information ChatGPT needs to know.
- Surveys and Interviews - Conducting surveys, interviews, or focus groups in your domain can generate new data to train ChatGPT. Ask open-ended questions about topics you want ChatGPT to discuss, and use the responses as training data.
The more variety of content you include, the broader your ChatGPT's knowledge will be for ChatGPT to learn
2.) Prepare Your JSONL Text Dataset
To train ChatGPT, you'll need to format your data in JSONL - one JSON object per line.
Here's a simplified example of JSONL training data:
{
"prompt": "How do I use your product?",
"response": "To use our product, first sign up for an account on our website. Then you can login and access all the features."
}
{
"prompt": "How much does your service cost?",
"response": "We offer a free 30-day trial. After the trial period, plans start at $10/month."
}
3.) Organize Data by Topic
Group data by topic or subject to make it easier to train ChatGPT on specific areas of knowledge. For example, group all data on product features together and all data on common customer questions together.
Here's a more advanced example of JSONL text data:
{
"prompt": "[Your prompt here]",
"variables": {
"URL": "[URL]",
"USPS": "[USPS information]",
"testimonials": "[Testimonials]",
"objections": "[Customer objections]",
"Audience": "[Target audience]"
},
"optimized_output": {
"headline": "[Optimized headline]",
"preview_text": "[Short, concise preview text]",
"introduction": "[Introduction line about yourself and company]",
"key_benefit": "[Statement of key product/service benefit]",
"CTA": "[Call to action]"
}
}
With enough examples illustrating your desired tone, terminology, messaging, etc., ChatGPT will start conforming new outputs based on your training data
4.) Clean and Preprocess the Documents
Before model training, we need to clean and preprocess the text data:
- Fix any formatting issues like unusual spacing or symbols
- Break content down into individual sentences, 1 sentence per line
- Shuffle all sentences so order is random
- Remove exact duplicate sentences
This
Python script helps automate data cleaning and preprocessing.
As a rule of thumb, aim to compile at least 1k unique, high quality sentences for the training dataset. More data is generally better for accuracy.
Or you can always use a no-code GPT-4 instruction fine-tuning tool like Performify.
3.) Run Training Loop on Business Documents
Now we can train this model architecture on your business text dataset with the below training loop:
# Load text dataset
with open('my_business_docs.txt') as f:
texts = f.read().splitlines()
# Tokenize text
tokenizer = claire.tokenizers.Gpt2TokenizerFast()
train_tokens = tokenizer(texts)
# Define training parameters
epochs = 10
batch_size = 32
lr = 3e-4 # Learning rate
# Training loop
for e in range(epochs):
for i in range(0, len(texts), batch_size):
# Get batch & compute loss
batch = train_tokens[i:i+batch_size]
loss = model(batch)
# Update model gradients
loss.backward()
optimizer.step()
# Print loss
print(f'Epoch {e+1}, Loss {loss}')
Here we:
- Tokenize the text into numbered IDs
- Get batch of sentence tokens
- Pass batch into model to predict next tokens
- Compute loss between prediction and actual
- Update model weights to minimize loss
After 5+ epochs of training, the model has "digested" all our unique business documents and can now generate human responses based on that knowledge!
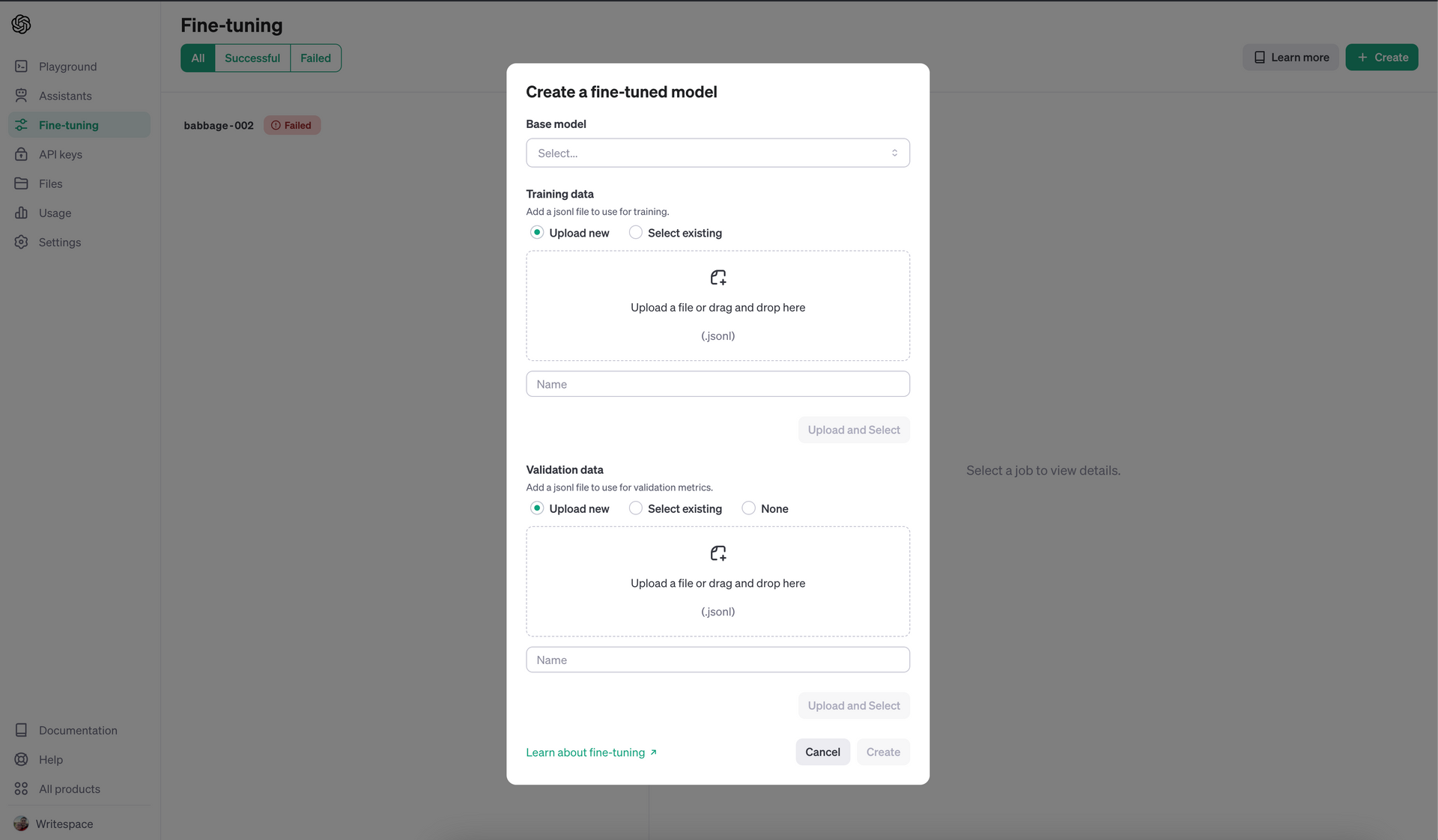
Now, Just Upload Your New Text Dataset into OpenAI's New Fine-tuner UI
The hard part is over and the next part is pretty easy, which can easily be followed in
OpenAI's guide to upload dataset for fine-tuning
This uses OpenCV for preprocessing and contour detection to isolate each text field. PyTesseract then extracts the text which can be automatically typed or pasted into the matching text fields on the web form.
Best Practices for Training ChatGPT
Follow these tips to get optimal results when training ChatGPT on your data:
- Provide lengthy, comprehensive prompts packed with key details.
- Use clear, direct instructions to explain exactly what you want ChatGPT to write.
- Train iteratively in a conversational flow, refining the responses over multiple interactions.
- Upvote the best responses and downvote poor or incorrect ones.
- Supply multiple reference documents and links as sources for the AI to pull knowledge from.
- Be patient. It takes many training examples for ChatGPT to learn your content style and business specifics.
The Best No-Code AI Fine-Tuning Tool
Training ChatGPT on your data unlocks its full potential for generating accurate, customized copy.
But it's time intensive, confusing, and expensive to do. That's why we create Performify, which is the easiest way to fine-tune AI on your custom knowledge base.

Latest Blog Articles




Comparisons
Performify vs MakeForms
Performify vs Tally
Performify vs Fillout
Performify vs Feathery
Performify vs involve.me
© 2024 Performify LLC.
All Rights Reserved